
點閱率 | 1056 次
人工智慧與AlphaGo
文/陳俊廷
第一台超級智慧機器是人類需要完成的最後一項發明,前提是這台機器足夠聽話,會告訴我們如何控制它。-I.J. Good
AlphaGo與韓國棋王李世乭的圍棋大戰是這陣子資訊產業中最轟動的消息,賽前許多專家都看好李世乭能夠獲勝,想不到竟然一勝難求,這也讓很多的民眾開始擔心人工智慧是否已經開始入侵我們的生活中,人類要被天網支配拉等等的言論開始湧現,到底為什麼AlphaGo在圍棋上贏過人類,造成這麼大的轟動,而AlphaGo又有什麼特別的地方呢?本篇文章將為大家介紹可能會是人類最後的一項發明「人工智慧」。
│人工智慧的發展│
1950年,還是個學生的馬文‧閔斯基教授(Marvin Lee Minsky)以3,000個真空管和轟炸機上一個自動指示裝置做出了人類史上第一台神經網路電腦SNARC(Stochastic Neural Analog Reinforcement Calculator),人工智慧從原本僅是一個數學概念瞬間轉為實體,這也讓許多許多學者專家,像艾倫‧圖靈(Alan Mathison Turing)、約翰‧麥卡錫(John McCarthy)等紛紛投入人工智慧這個領域,但好景不常,因為當時硬體上的限制以及演算法本身的缺陷,專家們很快就遇到了瓶頸,人工智慧就此步入寒冬。
│ SNARC(圖片來源:http://cyberneticzoo.com/mazesolvers/1951-maze-solver-minsky-edmonds-american)
一直到80年代後期,人們發現將統計學運用在人工智慧的領域能帶來很好的成果,且隨著電腦運算能力的提升、更加優化的演算法,以及大資料集和資料採擷等技術的幫助,人工智慧才又重新獲得人們的目光。
│AlphaGo與人工智慧│
從定義上來看,人工智慧區分為強人工智慧(Artificial General Intelligence)與弱人工智慧(Artificial Narrow Intelligence)兩種註1。強人工智慧泛指擁有意識、感性,能做出複雜決策、溝通、計畫甚至擁有學習及創新能力,而弱人工智慧,並不具有類似人類的認知思考能力,只處理特定的問題。以上述定義來看AlphaGo算是弱人工智慧,跟你手上的iPhone siri本質上沒太大的差別,那大家可能會質疑,如果AlphaGo不會思考那它是如何下棋的,如果要了解AlphaGo,首先我們需要先了解AlphaGo背後到底是一個什麼東西。
│“DeepMind”構成AlphaGo的卷積神經網路系統│
Google DeepMind是由 Google在2014年收購的英國人工智慧公司DeepMind開發一套卷積神經網路(Convolutional Neural Network)。卷積神經網路是一種深度學習(deep learning)系統常用於圖像或聲音辨識上,以往的圖像辨識需要先透過人工將特徵挑出,例如要辨識一隻狗,你可能要先跟電腦說,狗有4支腳、兩個耳朵、腳上有肉球等,再交由電腦辨識,但卷積神經網路不同,卷積神經網路透過多個卷積層的方式尋找特徵,可以自己從數據中找出特徵,而且卷積層(Convolutional layer)的數量越多,辨識出來的資料也就愈精準,所以假設想要讓電腦能夠辨識一隻貓,只要提供大量狗的照片給卷積神經網路訓練,它就能夠從中找出貓的特徵,從而辨識出貓這一個概念。

│ Google DeepMind
│卷積神經網路與圍棋的關係│
以往一直認為圍棋是人類最後的堡壘,主要原因在於圍棋本身的複雜度高達10172次方(西洋棋與象棋分別為10123次方與10160),所以幾乎不可能用傳統的MinMax搜尋法導出結果,就算是超超級電腦也辦不到,外加圍棋獲勝的規則不明確,不像象棋只要吃掉對方的帥或將就獲勝,所以很難提供電腦一個有效的評估函數,but,人生就是這個but,圍棋的規則是雙方交替使用黑白子圈地,且下子後不能移動,剛好卷積神經網路很適合用來處理圍棋這個問題,我們不需要告訴AlphaGo規則,只要輸入一大堆棋譜到卷積神經網路,AlphaGo就可以自行推導出圍棋的規則以及策略。
│戰勝自己│
當AlphaGo學得規則後,下一步就是嘗試讓它跟自己練習,準備兩台的AlphaGo,其中一台是有經過部分訓練的專家,另一台是基礎版的學生,透過蒙地卡羅對局搜尋法(Monte Carlo tree search)讓兩台AlphaGo互相對戰,如果學生AlphaGo贏了,那就攻守互換,學生變專家,專家變學生,不斷的重複,這種訓練方式稱為增強式學習(Reinforcement Learning),藉由跟過去的自己對戰來增強之前所學到的棋步。
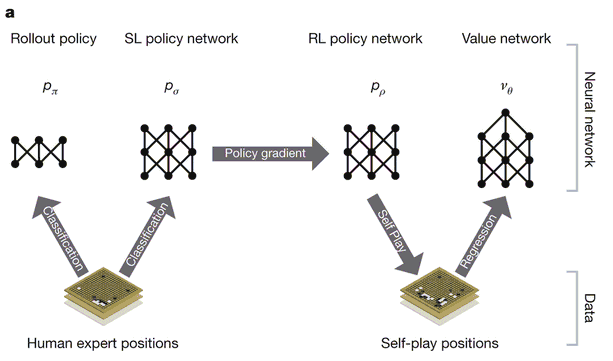
│ AlphaGo的訓練架構 (圖片來源http://www.nature.com/nature/journal/v529/n7587/full/nature16961.html#figures)
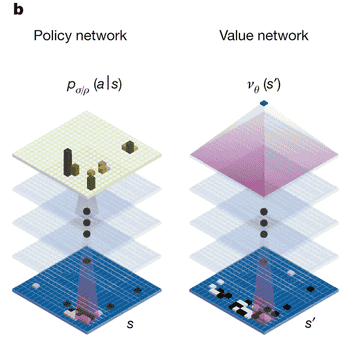
│ 策略網路與價值網路 (圖片來源http://www.nature.com/nature/journal/v529/n7587/full/nature16961.html#figures)
│人工智慧的未來│
「DEEP BLUE」在1997年打敗西洋棋王卡斯巴羅夫;「Watson」在2014年的益智問答節目Jeopardy!中打敗兩位世界紀錄保持人,獲得冠軍以及100萬美元的獎金;「AlphaGo」在2016年打敗韓國棋王李世乭,獲得了AlphaGo九段的名號,種種跡象都讓人覺得人工智慧是不是已經威脅到人們的生活了,未來我們的工作權會不會被機器取代,統計學家 I.J. Good曾經指出如果人工智慧像人類一樣能演化變得更聰明,我們確實可能會面臨「智慧爆炸」 (intelligence explosion)註2的問題,最終導致機器的智慧超過我們,且超過的程度大於人類比蝸牛的程度,不過就目前現況來看,很多對人類來說輕而易舉的事,對機器來說仍然很困難,或許不用太擔心人類被取代的日子那麼快來到。
│備註│
註1:人工智慧分類還有第3種,被稱為「超人工智慧」,泛指各方面皆優於人類的系統,也是本文中提及的超級智慧,但由於目前技術仍無法達成,故並不屬於正式分類。
註2:「智慧爆炸」是1965年統計學家 I.J. Good於 1965 年提出,當時他說,二十世紀內人類就會設計出遠超過任何智力的超級機器,超級智慧機器就會生產更優良的機器,之後必定出現「智慧爆炸」,人類智慧會被遠遠拋在後頭。
│參考資料
1.http://technews.tw/2016/02/11/ai-history/ link
2.https://dotblogs.com.tw/allanyiin/2016/03/12/222215 link
3.Snarc(Stochastic Neural Analog Reinforcement Calculator link
4.Mastering the Game of Go with Deep Neural Networks and Tree Search